
Hardware-Inspired ShiftAddNets
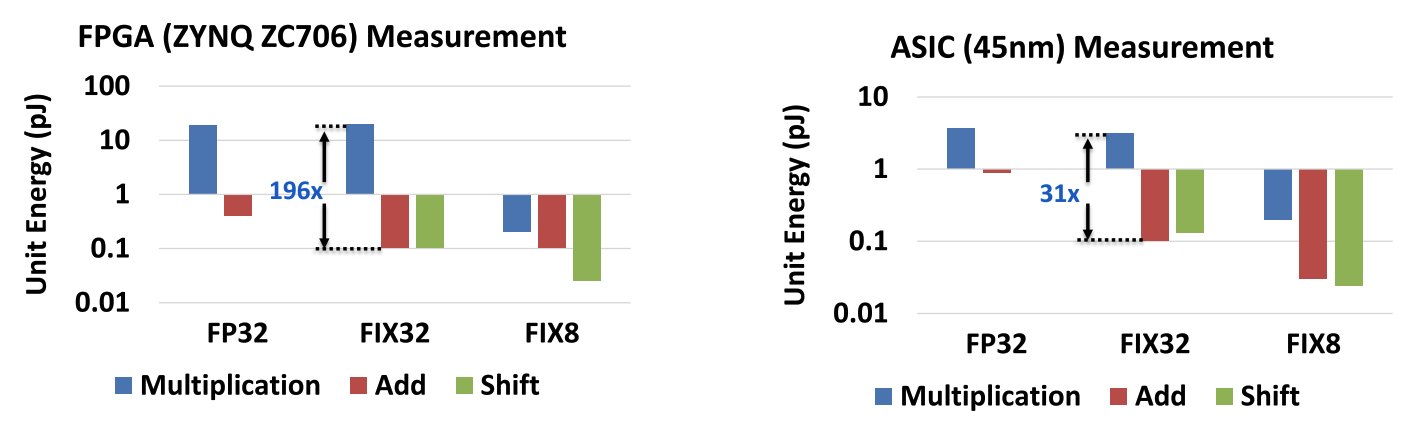
Multiplications dominate the cost of deep networks, both in silicon area and in energy. Measured on a ZYNQ-7 ZC706 FPGA and on a 45nm ASIC, a single multiplication costs up to 196× and 31× more energy than the equivalent addition or bitwise shift, respectively—a gap that widens further at lower precision. Computer architects have exploited this gap for decades: any multiplication by a constant can be rewritten as a sequence of bit-shifts and additions, which is exactly how multipliers are avoided in low-power digital signal processing hardware. The series of work below, spanning five years and four papers, asks how far this hardware “shortcut” can be pushed into deep learning—starting from CNNs trained from scratch, all the way to today’s large language models (LLMs) reparameterized with no retraining at all.
Combining shift and add: ShiftAddNet. Before ShiftAddNet, two lines of work had already tried to remove multiplication from CNNs, each leaning on a single primitive. DeepShift replaced multiplications with bitwise shifts, but shifts can only represent powers of two, so they only approximate the original mapping and lose expressiveness. AdderNet went the other way and replaced all multiplications with additions alone; additions are surjective and don’t lose expressiveness in principle, but reproducing a multiplicative mapping out of pure additions is parameter-inefficient. ShiftAddNet (NeurIPS 2020) combines both primitives instead of picking one: every convolution and fully-connected layer is reparameterized into a cascade of a bit-shift layer followed by an add layer, trained end-to-end from scratch.
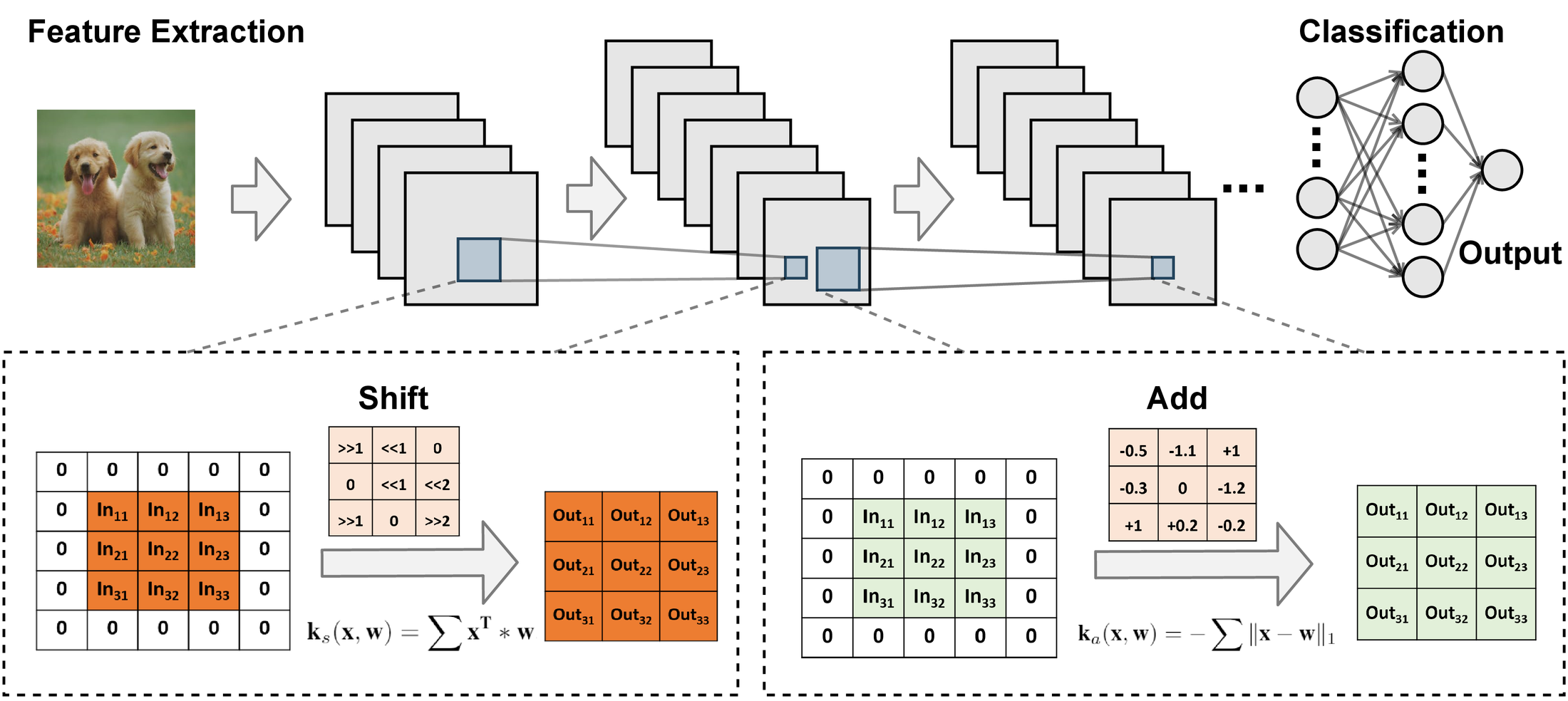
The two primitives turn out to be naturally complementary: shifts provide coarse-grained, large feature-scale adjustments, while adds provide fine-grained corrections—together they recover the full expressiveness that shift-only or add-only networks lose. This combination lets ShiftAddNet achieve up to 90% and 82.8% energy savings over AdderNet and DeepShift, respectively, at comparable or better accuracy, and the savings were measured with real on-board energy numbers from a ZYNQ-7 FPGA rather than simulation—reducing the hardware-quantified energy cost of training and inference by over 80% compared to standard DNNs.
Learning where to apply it: ShiftAddNAS. ShiftAddNet, like AdderNet before it, is still a pure multiplication-free network, and pure multiplication-free networks consistently under-perform their full-precision counterparts in accuracy on harder vision and language tasks—multiplications are simply more expressive than any fixed combination of shifts and adds. ShiftAddNAS (ICML 2022) reframes the question: rather than replacing every multiplication, why not let neural architecture search decide where it’s worth keeping multiplication and where shift-and-add suffices? It builds a hybrid search space mixing multiplication-based operators (convolution, attention) with multiplication-free ones (shift, add), searched together with a new weight-sharing strategy. This is necessary because the weights of multiplicative and additive operators follow different distributions (Gaussian vs. Laplacian)—sharing weights naively across them either hurts accuracy or blows up the search space. Searched on both CNNs and Transformers, the resulting hybrid networks achieve up to 7.7% higher accuracy on vision tasks and 4.9 better BLEU score on machine translation than state-of-the-art alternatives, while still delivering up to 93% energy savings and 69% latency reduction—the first sign that adaptively mixing multiplication with shift-and-add, rather than removing it outright, is the better trade-off.
Skipping pretraining: ShiftAddViT. ShiftAddNet and ShiftAddNAS both assume you can afford to train (or search) a network from scratch. That assumption breaks down for Vision Transformers (ViTs), where pretraining a strong backbone is far more expensive than training a small CNN, and where cost is split between two very different components—attention’s MatMuls and the MLPs. ShiftAddViT (NeurIPS 2023) reparameterizes pre-trained ViTs directly, with no training from scratch. It treats attention and MLPs differently: queries and keys are first mapped into binary codes in Hamming space, which lets the QK and attention-value MatMuls be reparameterized into additive kernels at essentially no accuracy cost; the remaining MLPs and linear layers are reparameterized with shift kernels, which is cheap but—echoing ShiftAddNAS’s lesson—hurts accuracy if applied uniformly. The fix is again adaptive, just at a finer grain: a mixture-of-experts (MoE) framework with a latency-aware load-balancing loss routes each token to either a multiplication expert or a shift expert depending on how sensitive that token is, so the decision of “where multiplication is worth it” is now made per-token at inference time rather than per-operator at search time.
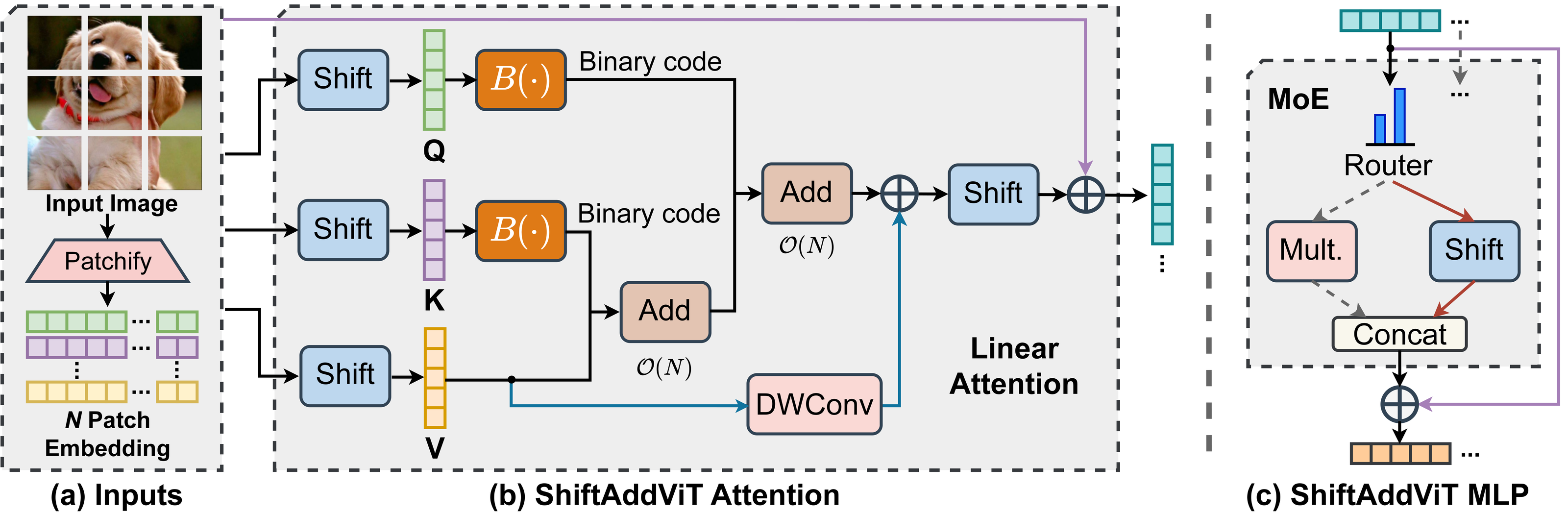
Implemented with custom TVM kernels for practical GPU deployment, ShiftAddViT achieves up to 5.18× latency reduction on GPUs and 42.9% energy savings across various 2D/3D Transformer-based vision tasks, while maintaining comparable or even higher accuracy than the original ViTs—all without training from scratch.
Going fully post-training, at LLM scale: ShiftAddLLM. Even the light fine-tuning ShiftAddViT relies on to train its MoE router becomes impractical at LLM scale, where a single fine-tuning run can cost as much as the original pre-training. ShiftAddLLM (NeurIPS 2024) pushes the idea to its limit: reparameterizing pretrained LLMs into shift-and-add operations entirely post-training, with no fine-tuning or retraining step at all. Each weight matrix is quantized into binary matrices with group-wise scaling factors, turning multiplications into shift-and-add operations that are executed efficiently via LUT-based query-and-add kernels.
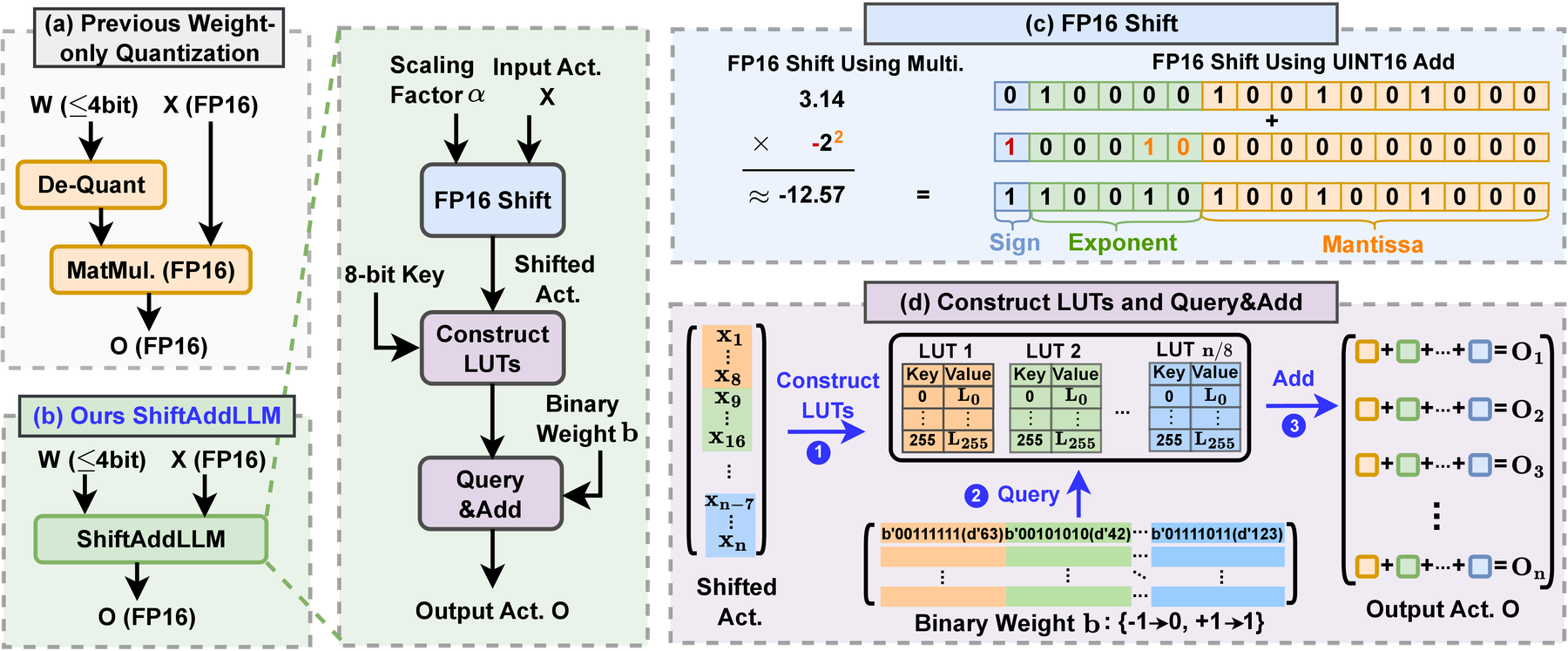
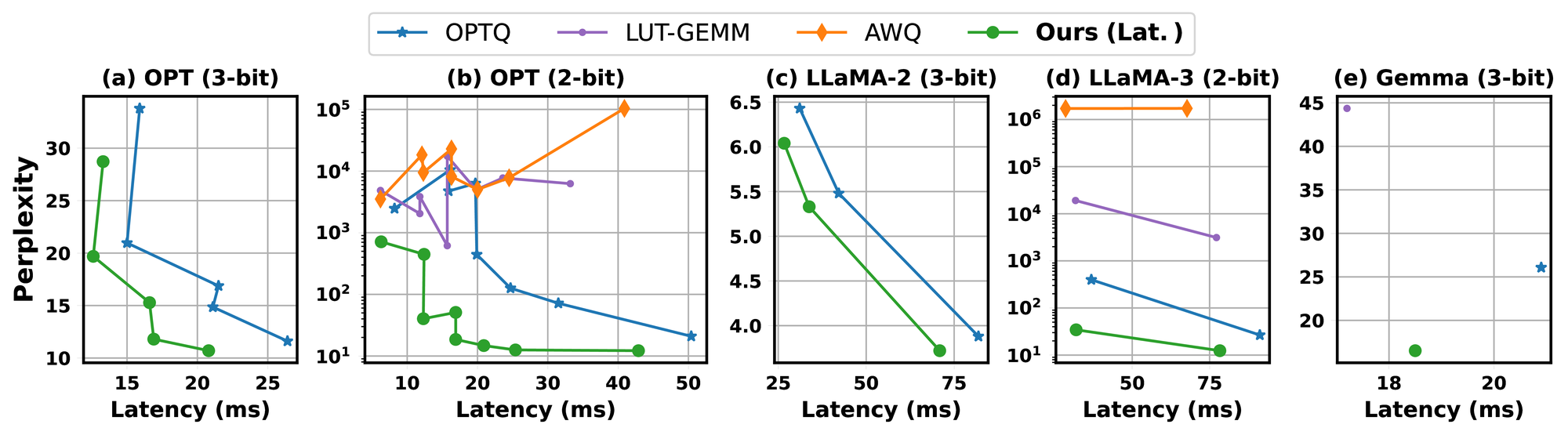
With no retraining available to recover accuracy, ShiftAddLLM moves the “where to be adaptive” decision once more—this time to the bit level. A multi-objective optimization jointly minimizes weight and output-activation reconstruction error rather than weight error alone, and an automated, mixed bit-allocation strategy assigns more bits to layers and blocks that are more sensitive to reparameterization and fewer bits to the rest, the same hybrid principle as ShiftAddNAS and ShiftAddViT, now expressed as how many bits rather than which operator. Across five LLM families (including OPT, LLaMA-2, LLaMA-3, and Gemma) and eight tasks, ShiftAddLLM consistently dominates the perplexity-latency trade-off, improving average perplexity by 5.6 and 22.7 points over the most competitive quantized LLMs at comparable or lower latency at 3-bit and 2-bit precision, respectively.
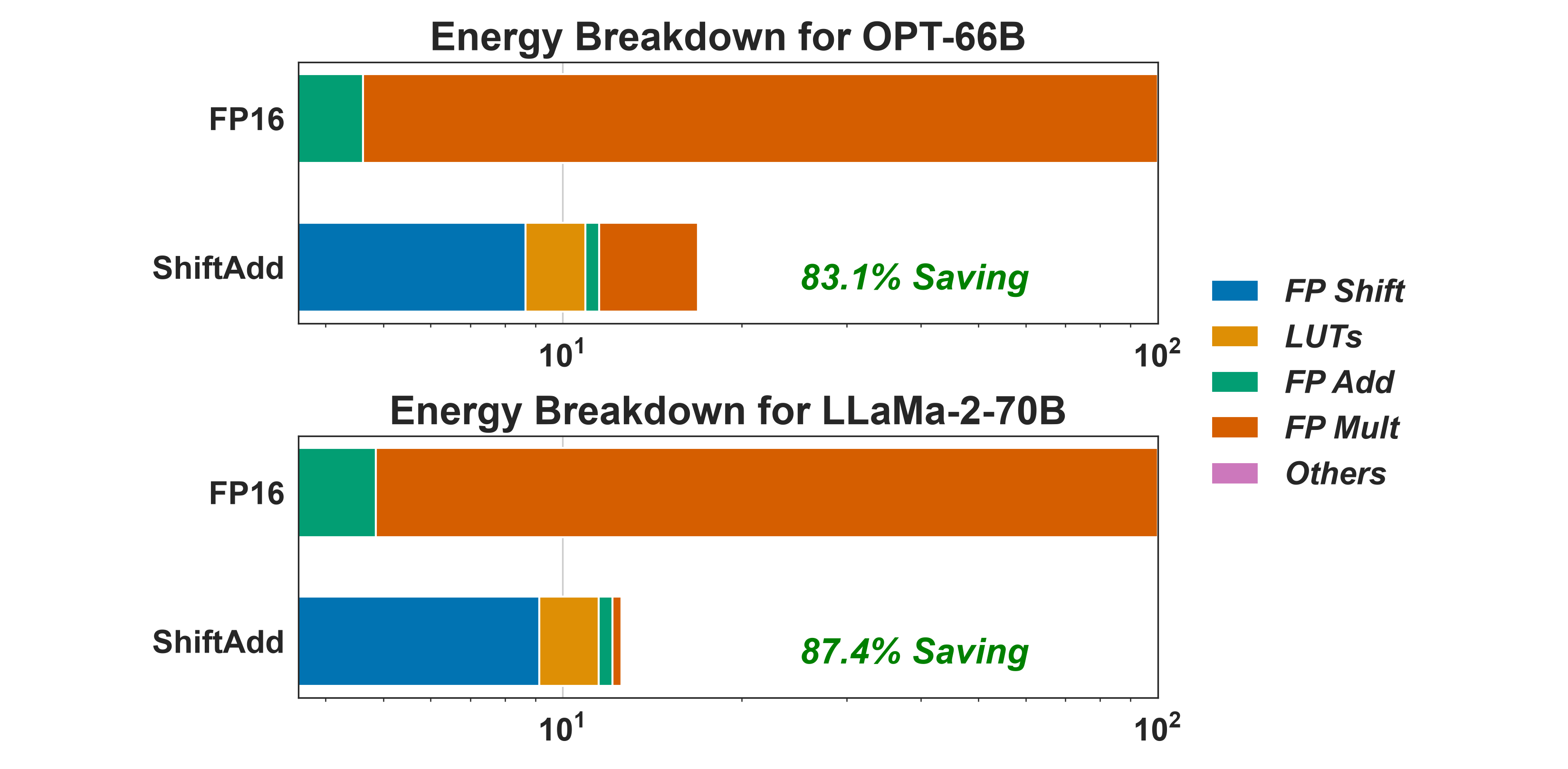
Summary. Across four papers and four eras of network design—training a CNN from scratch, searching hybrid architectures with NAS, lightly fine-tuning a pretrained ViT, and reparameterizing a pretrained LLM with no retraining whatsoever—the same two ingredients keep reappearing: bitwise shifts and adds as multiplication’s cheap substitutes, and an adaptive mechanism that decides where the substitution is worth making, whether that’s per-operator (ShiftAddNAS’s architecture search), per-token (ShiftAddViT’s mixture of experts), or per-bit (ShiftAddLLM’s mixed allocation). The end-to-end payoff compounds: applied to a 70B-parameter LLaMA-2 model, this same shift-and-add reparameterization cuts whole-model energy by 87.4% over FP16.
We are also working on bringing all four methods together under TorchShiftAdd, for building energy-efficient, multiplication-less models.