
Efficient Image Editing via HiLo-Token
Creative image editing features such as Photoshop’s Remove Tool and Generative Fill are used by millions of customers and account for a large share of Photoshop and Lightroom traffic; within 28 days of the Photoshop v27.0 release, 1.1 million of 3.3 million users engaged with Generative Fill, generating 36.2 million interactions. Serving these features at scale is becoming more expensive as the field moves from convolution-based U-Nets to Diffusion Transformers (DiTs), which are roughly 6x costlier to serve in the cloud despite having 1.8x fewer parameters. Below is a summary of HiLo-Token, an Adobe Tech Report (2026) that tackles this serving cost problem through input-adaptive token compression.

The Latency Bottleneck. HiLo-Token is built on top of MultiEdit (ME), a generalist image editing model fine-tuned from Adobe’s Firefly Image 3 foundation model. ME supports a wide range of editing tasks—removal, insertion, replacement, relighting, text editing, and more—and is further fine-tuned into task-specific specialists such as the production Erase and Generative Fill models. As shown below, ME is composed of a VAE encoder/decoder, a DiT backbone, a refiner, and an optional text encoder, and is trained through a supervised fine-tuning stage followed by few-step distillation.
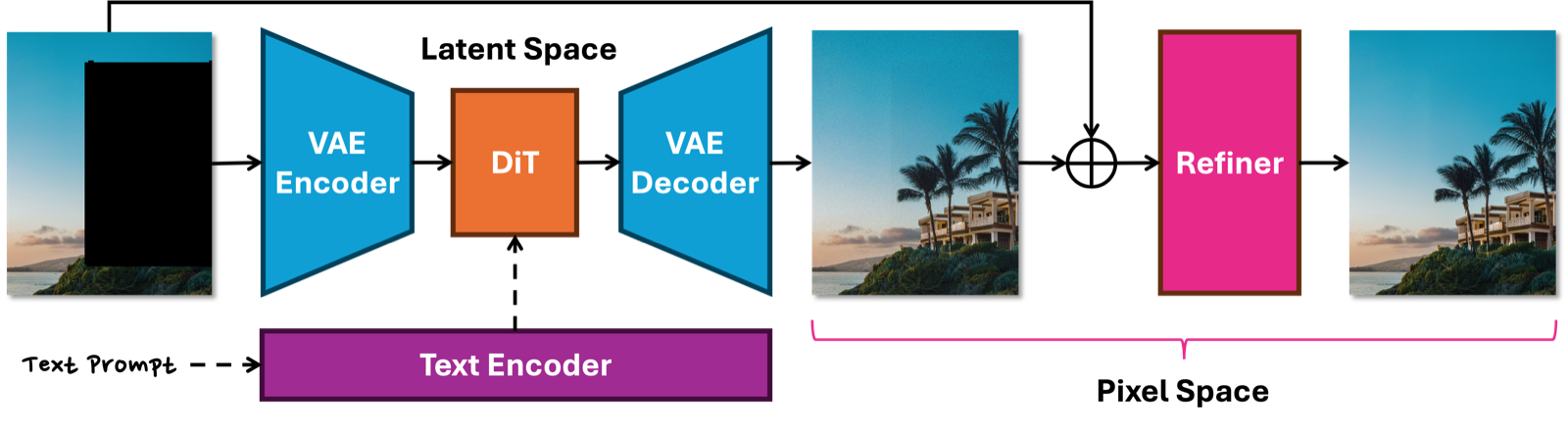
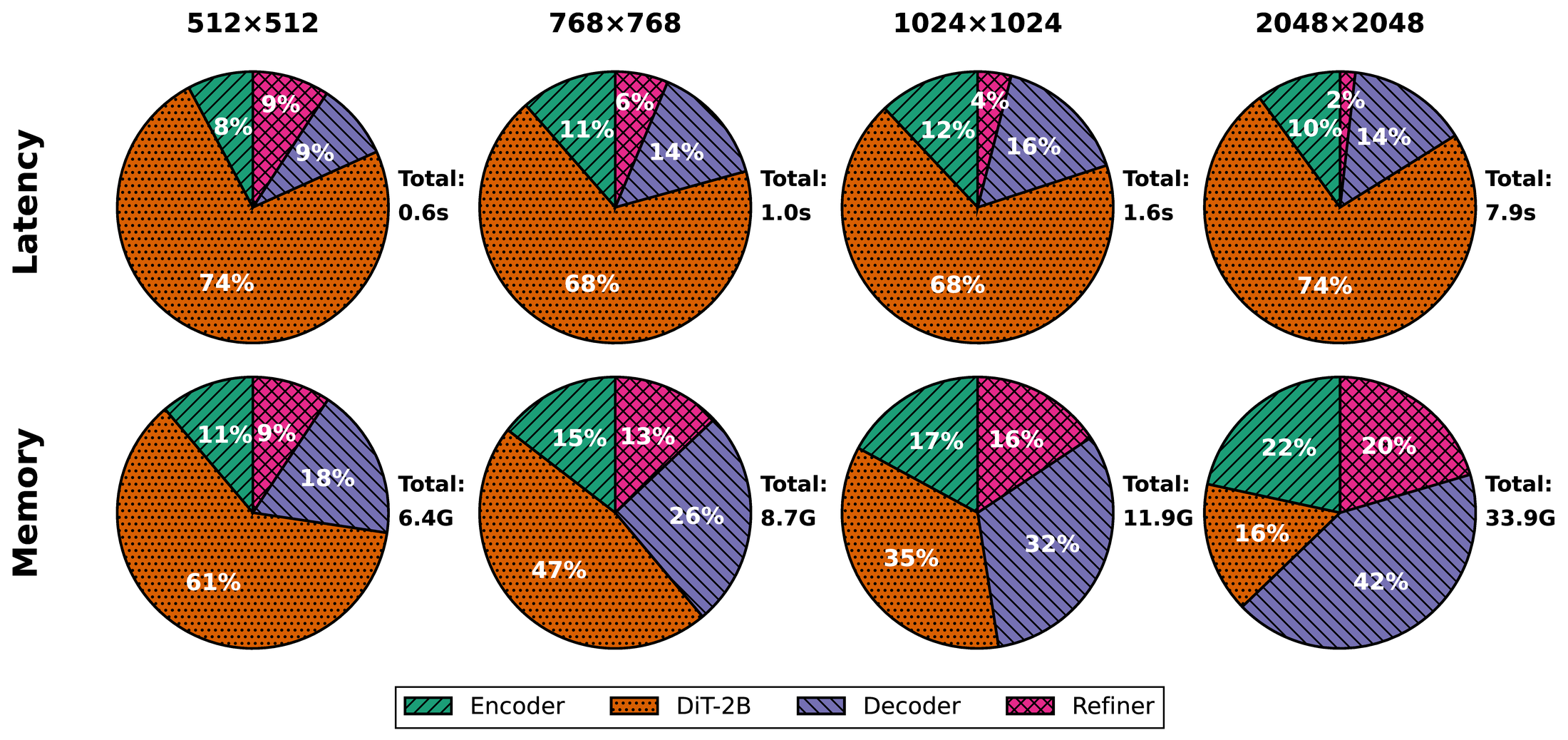
Profiling ME on an A100-80GB GPU reveals that the DiT module dominates end-to-end latency, accounting for roughly 70% of total runtime across resolutions from 512² to 2048², even after distilling from 50 timesteps down to 8. Interestingly, the DiT is not the memory bottleneck at high resolution: its memory share drops from 61% at 512² to only 16% at 2048², while the VAE and refiner increasingly dominate memory instead.
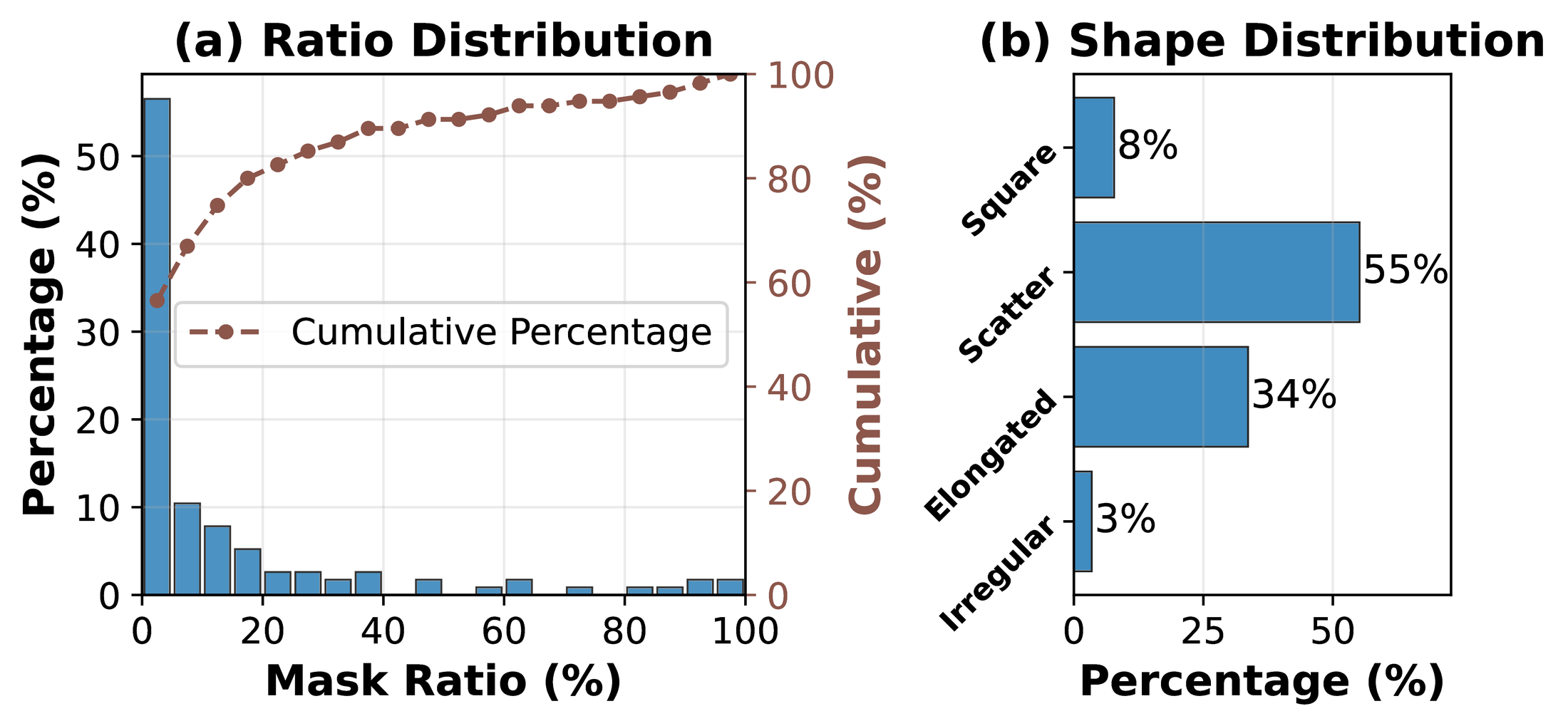
Why Tokens Can Be Compressed. Since latency is dominated by the DiT, and the DiT cost scales with the number of tokens it processes, the natural question is whether every token is actually needed. Analyzing real user editing masks shows that more than half of editing requests touch less than 10% of the image area, and 90% of requests edit no more than half the image; most masks are scattered or elongated holes rather than large regions. This means the DiT rarely needs to process the full image at full resolution—only the masked region and its relevant context.
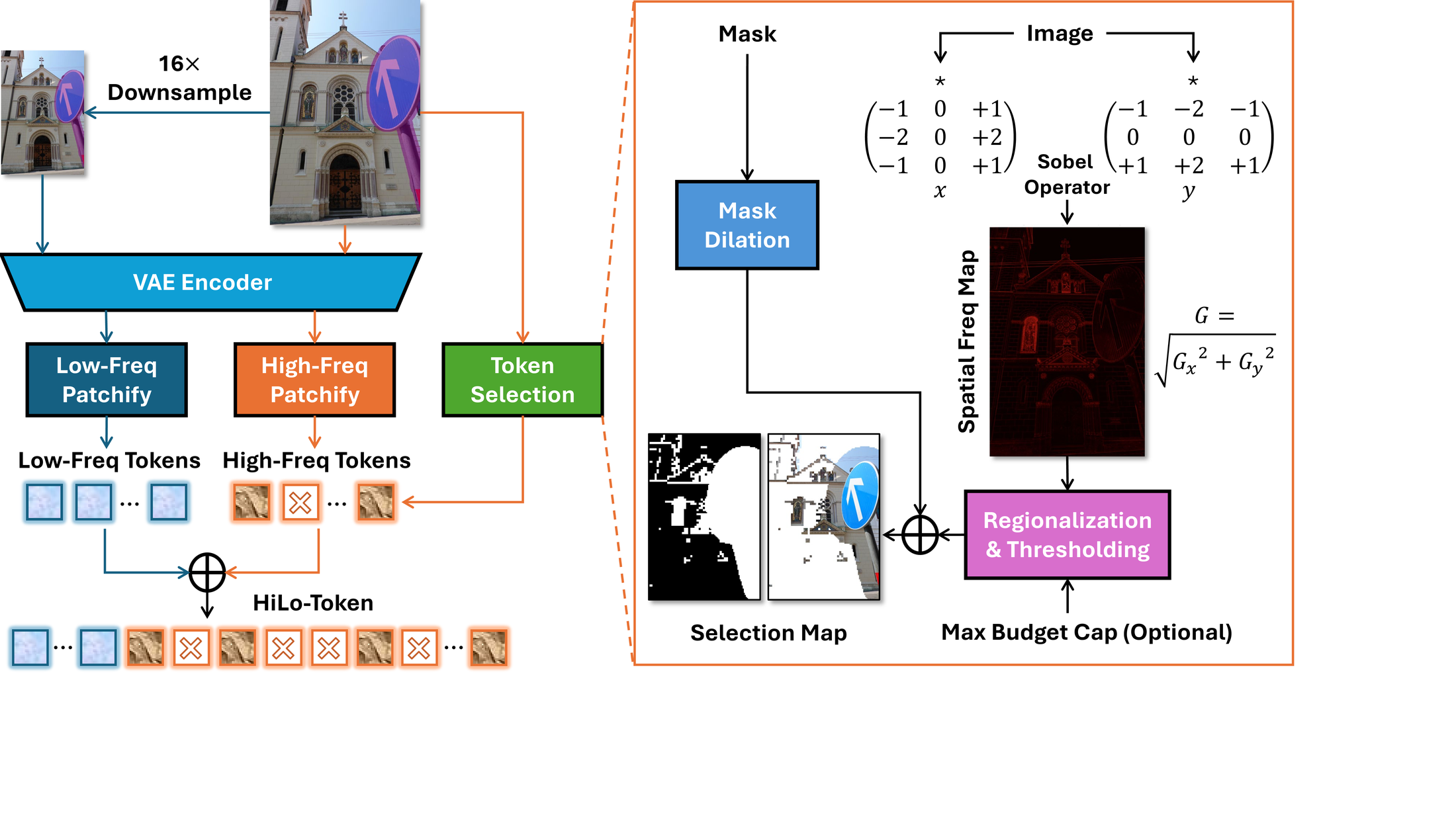
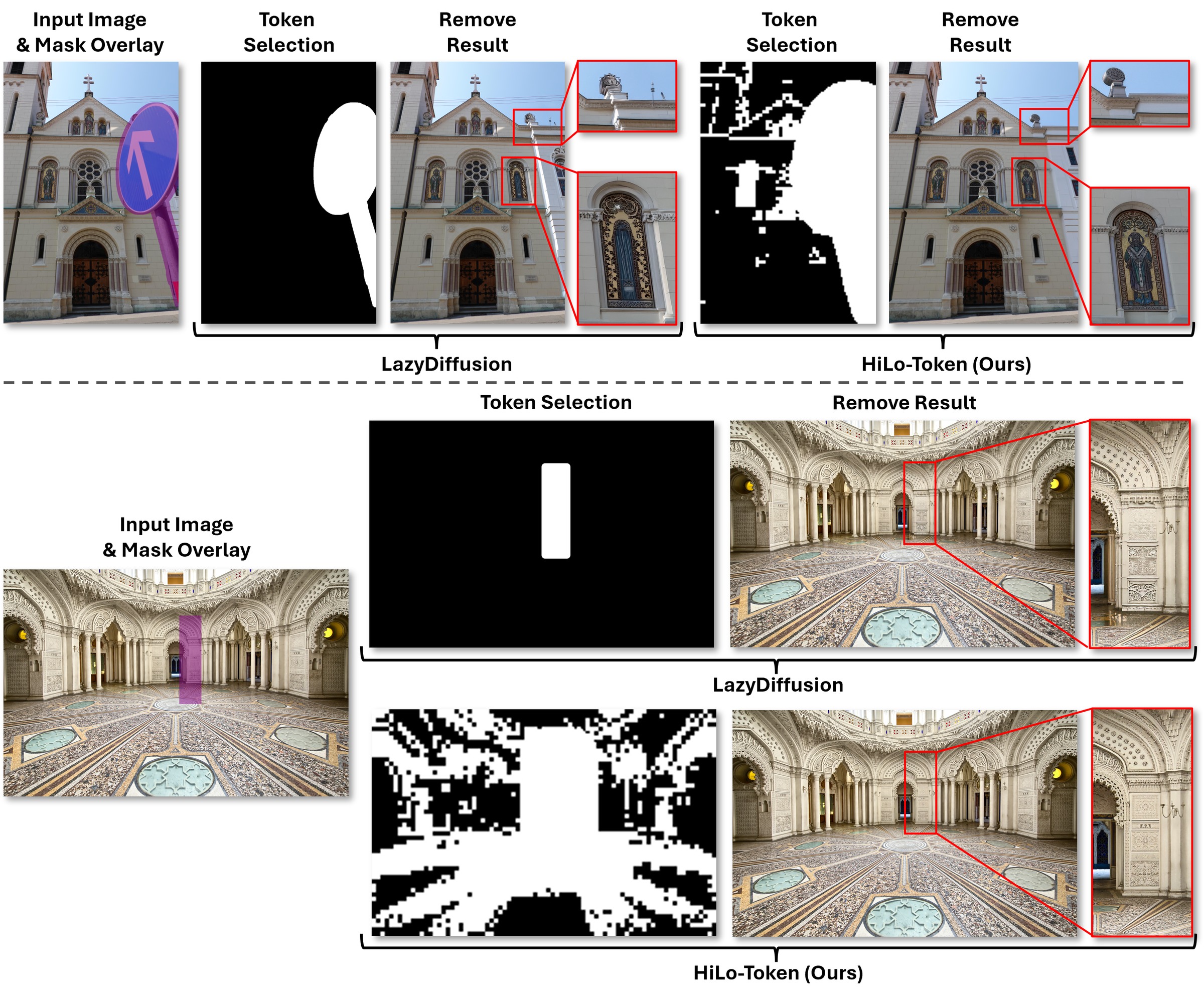
The HiLo-Token Framework. Building on LazyDiffusion, which by default keeps only tokens inside a dilated mask, HiLo-Token adds two parallel branches to recover the context that dilation alone discards, while keeping token selection cheap and input-adaptive:
- Low-frequency tokens: the input image is aggressively downsampled by 16× and encoded through the VAE and a low-frequency patch-embedding layer, producing a small number of tokens that capture blurry but globally consistent structure. Because there are so few of them, all are retained.
- High-frequency tokens: outside the dilated mask, a normalized spatial-frequency map is computed using only two Sobel convolutions (no learned context encoder), then pooled at the token-grid resolution to select coherent, high-frequency regions rather than scattered pixels. This avoids relying on attention-based importance, which can fail when the relevant content—like the occluded half of a symmetric pattern—has not yet been generated at early diffusion steps.
The selected high-frequency tokens are concatenated with the low-frequency tokens to form the final HiLo-Token representation fed to the DiT. The whole selection process costs roughly 10 ms, compared to the cost of a full transformer-based context encoder it replaces.
The figure below compares the token selection maps of LazyDiffusion and HiLo-Token on images with complex textures or occluded symmetric patterns. White regions denote selected tokens; HiLo-Token’s frequency-aware selection captures the symmetric high-frequency structure that correlation-based selection misses.
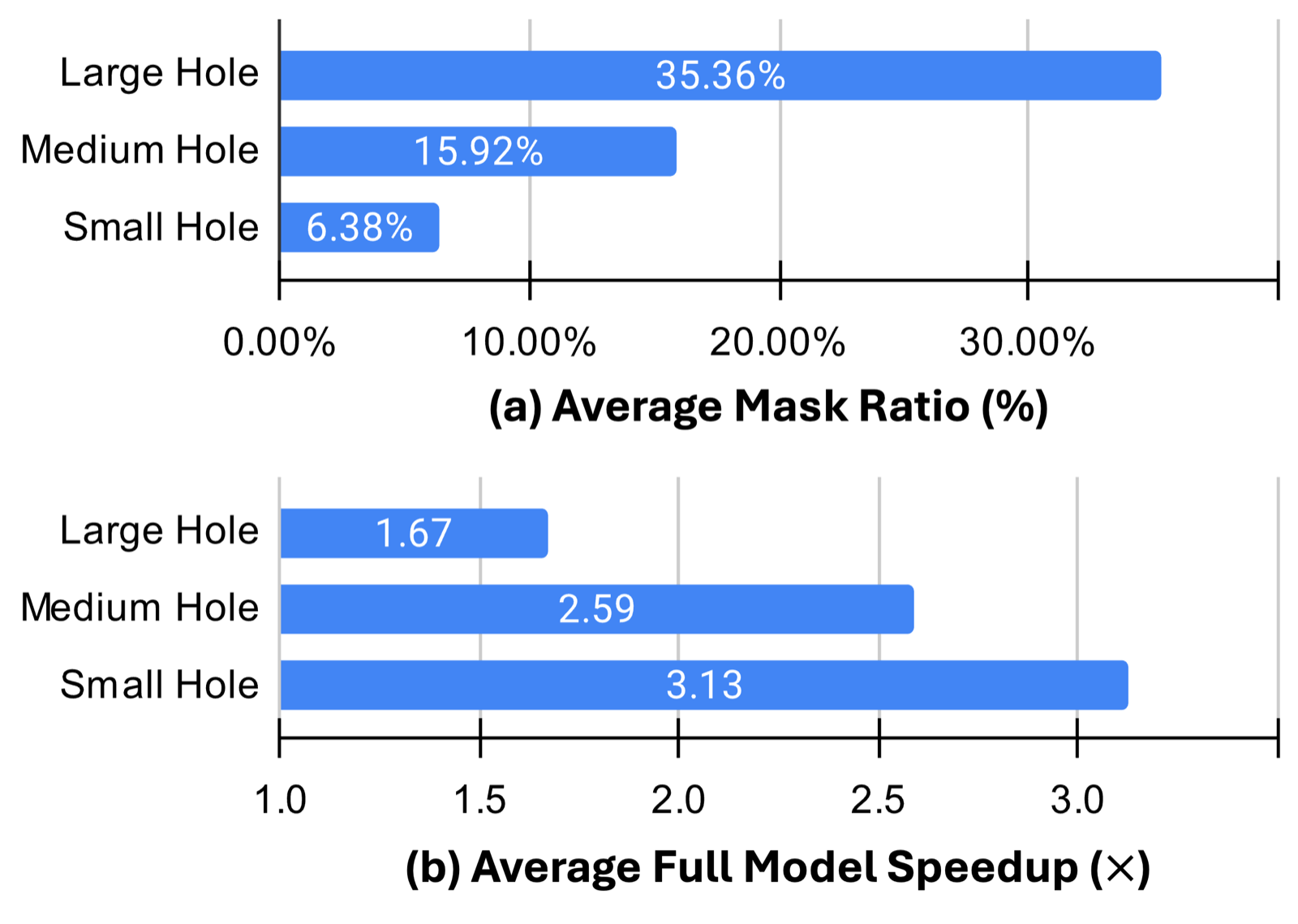
Results. HiLo-Token is applied during supervised fine-tuning of the ME specialists and remains compatible with the subsequent DMD-style few-step distillation, which minimizes the KL divergence $D_{KL}(p_s | p_t)$ between the student and teacher output distributions. On 92 representative editing cases split into small, medium, and large mask-ratio groups (average ratios of 6.38%, 15.92%, and 35.36%), HiLo-Token accelerates the DiT by 1.67×, 2.59×, and 3.13×, respectively, translating to end-to-end speedups of 1.33×, 1.66×, and 1.77×.
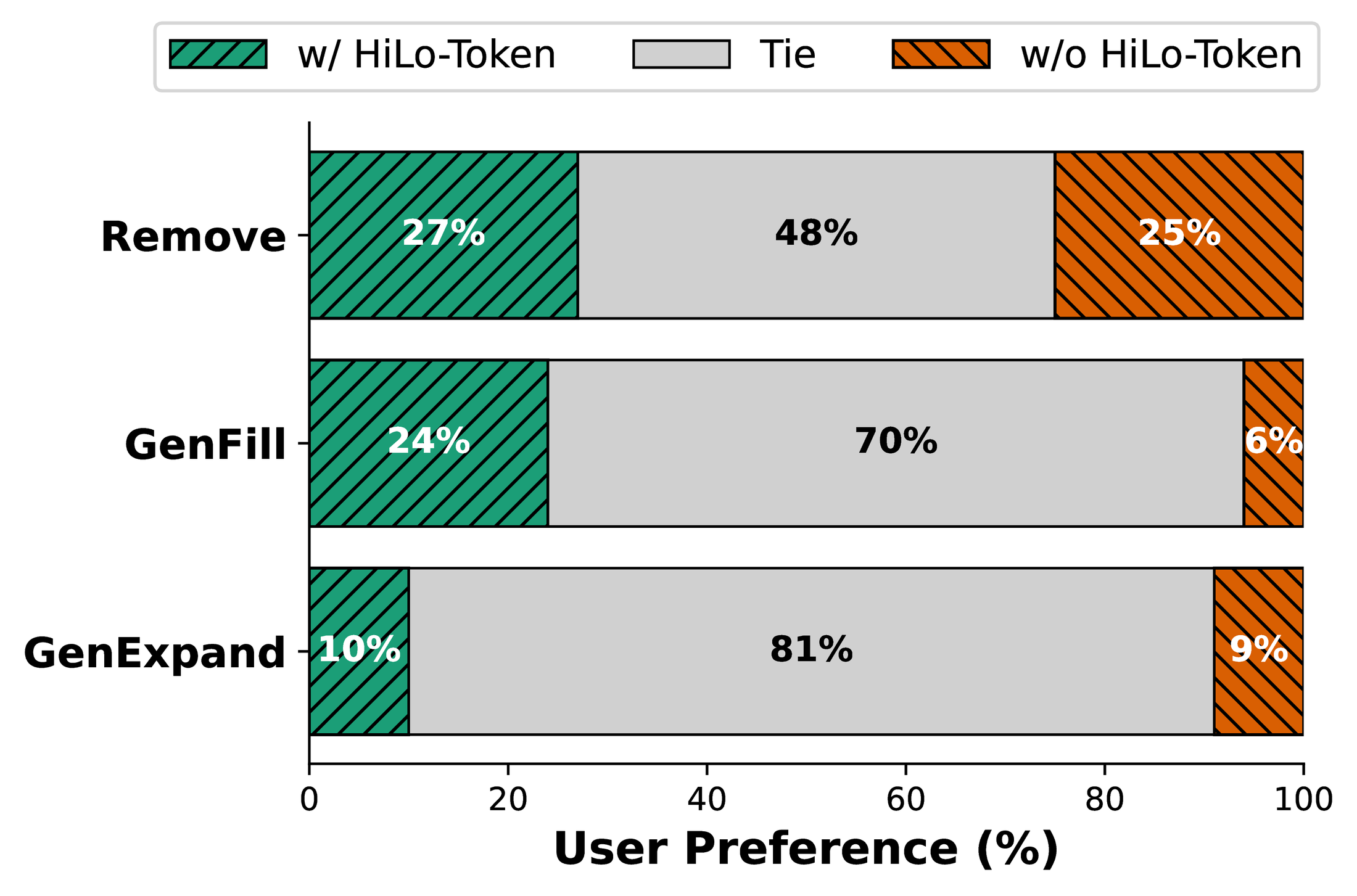
A user study comparing removal, generative fill, and generative expand specialists with and without HiLo-Token shows comparable editing quality, with tie rates of 48%, 70%, and 81% across the three tasks, and no consistent quality regression. HiLo-Token is also fully compatible with FP8 quantization (up to 40% additional latency reduction) and further distillation to 5 steps (an additional 37.5% reduction), and these gains translate directly into production: serving the Remove feature with HiLo-Token reduces the number of required AWS p5.48xlarge nodes by 33%.

In short, HiLo-Token shows that principled, input-adaptive token pruning—guided by simple frequency cues rather than learned attention—can cut DiT serving costs substantially without sacrificing editing quality, and it is already powering the Remove Tool and Generative Fill experiences in the latest Photoshop.