
Integrated Eye Tracking System
Eye tracking is an essential human-machine interaction modality for VR/AR, enabling technologies like foveated rendering that require high throughput (>240 FPS), a small form-factor, and visual privacy. Existing systems fall short of these goals because of three bottlenecks: (1) bulky lens-based cameras impose a large form-factor and a high communication cost between camera and processor; (2) captured images contain a lot of redundancy, since only a small portion shows the human eye; and (3) state-of-the-art segmentation and gaze estimation DNNs require up to 16G FLOPs. EyeCoD (ISCA’22; IEEE Micro Top Picks’23) tackles all three with a camera-algorithm-accelerator co-design.
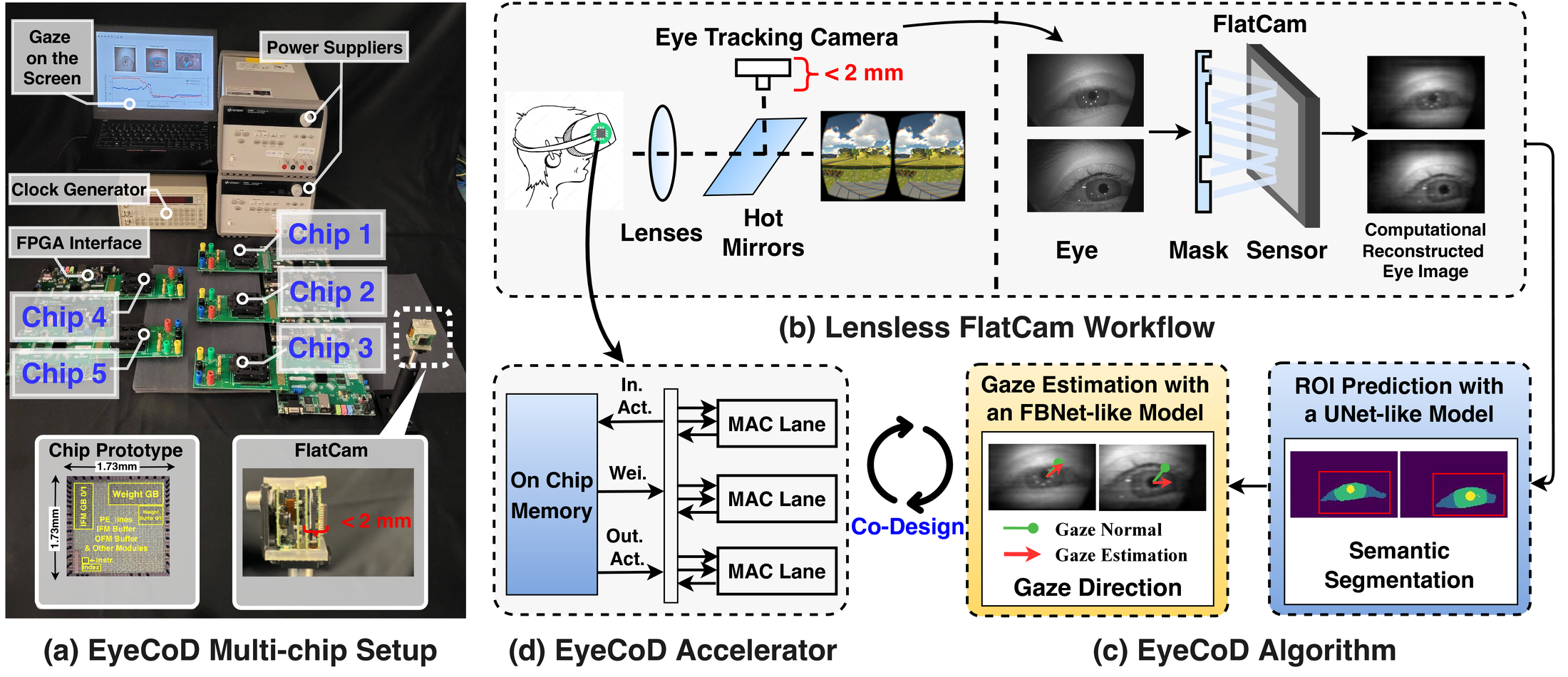
We zoom into each of these three levels—system, algorithm, and accelerator—below.

System level. EyeCoD replaces the lens-based camera with a lensless FlatCam, which is 5-10× thinner and >10× lighter. Removing the lens lets the backend accelerator sit right behind the sensor, cutting the camera-processor distance and communication cost, while the coded mask also makes captured measurements unrecognizable to the human eye, improving visual privacy.
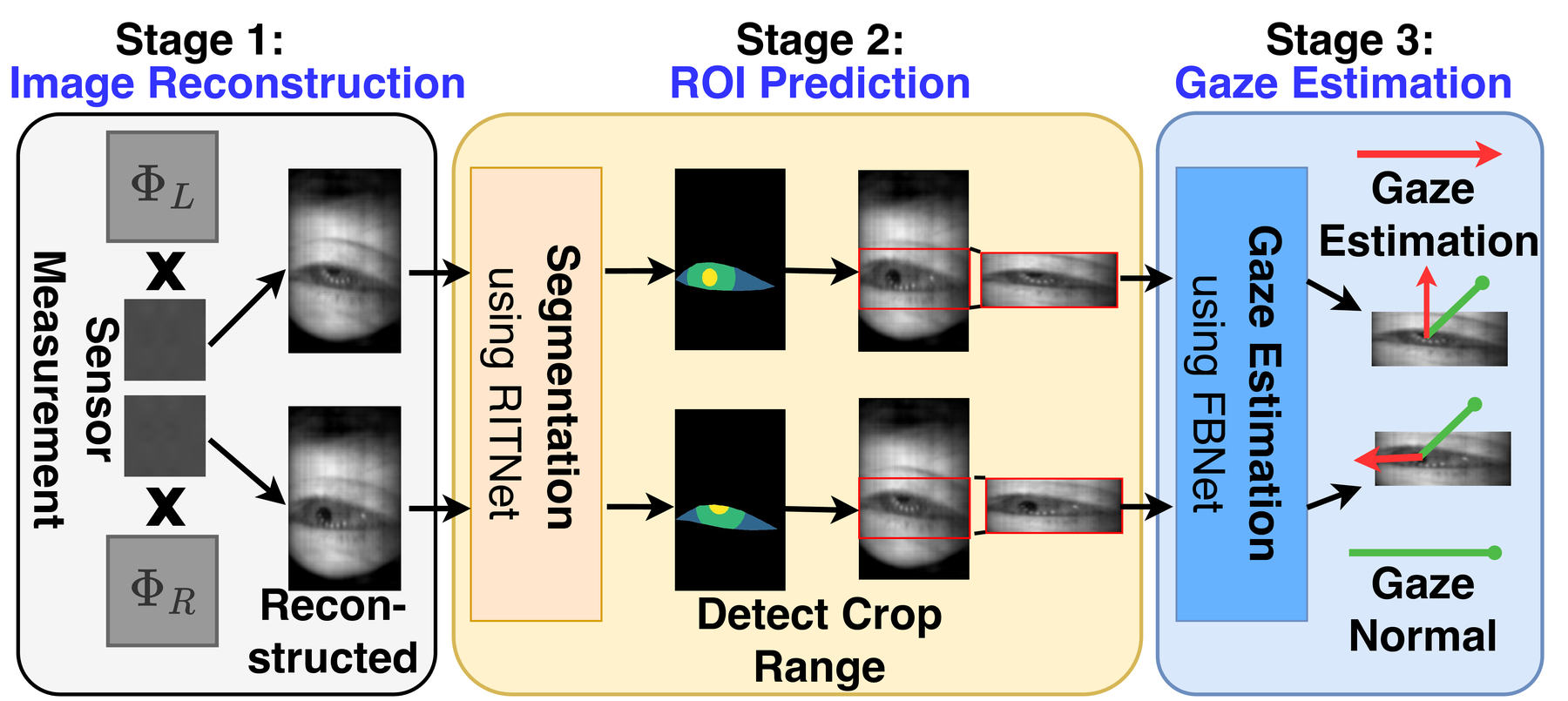
Algorithm level. EyeCoD uses a predict-then-focus pipeline: after reconstructing the image from the FlatCam’s measurements, a segmentation model (RITNet) predicts the region-of-interest (ROI) around the pupil, and a gaze-estimation model (FBNet-style) estimates gaze only from that ROI. Since eyes move much slower than gaze direction, ROI prediction only needs to run once every 50 frames, while gaze estimation runs every frame on the latest ROI.
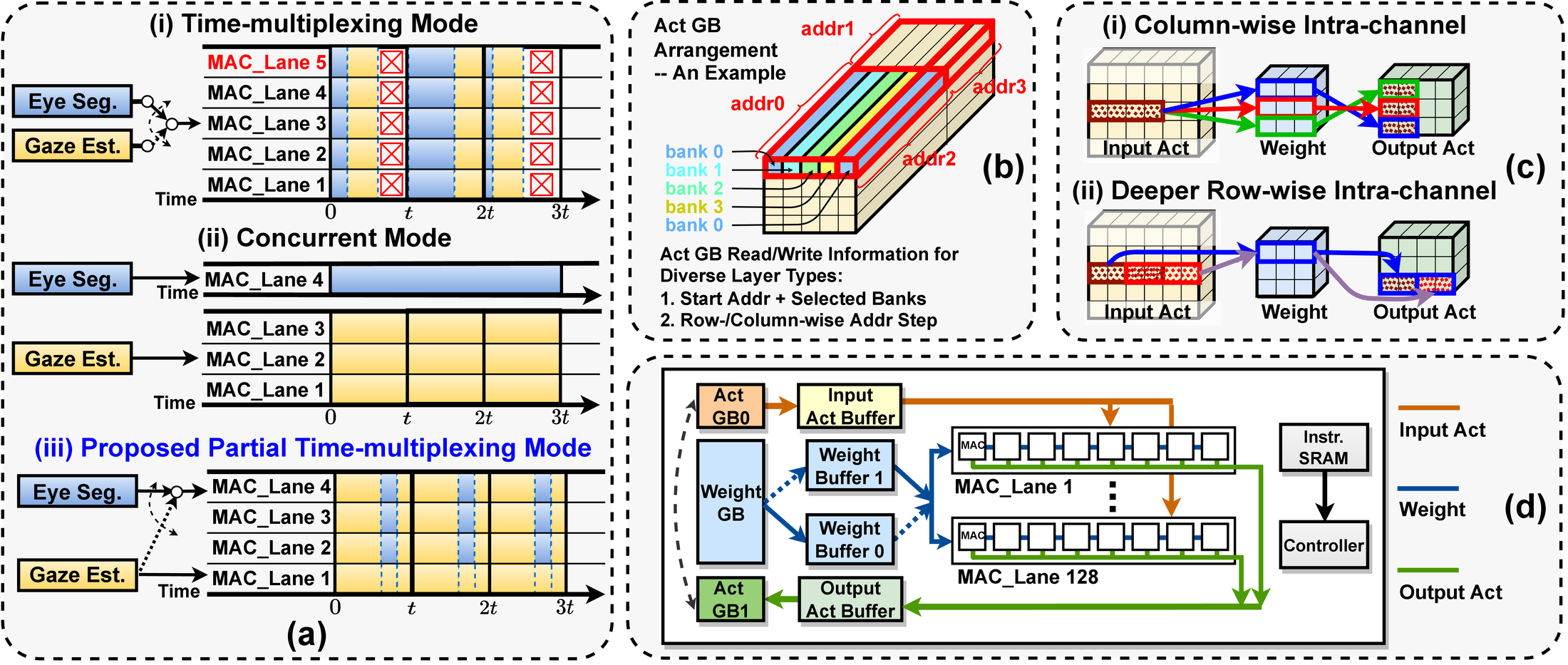
Hardware level. A dedicated accelerator further exploits this pipeline. EyeCoD’s sensing-processing interface folds the segmentation model’s first layer directly into the FlatCam’s coded mask, saving both compute and sensor-to-chip bandwidth. The accelerator also introduces a partial time-multiplexing workload orchestration mode that lets the gaze estimation model either fully own the MAC lanes or run concurrently with segmentation, avoiding the resource overhead of pure time-multiplexing and the reuse loss of pure concurrent execution. A dedicated activation-buffer arrangement and an intra-channel reuse dataflow for depthwise convolutions (which cost 33.6% of runtime for only 7.9% of FLOPs) round out the design.
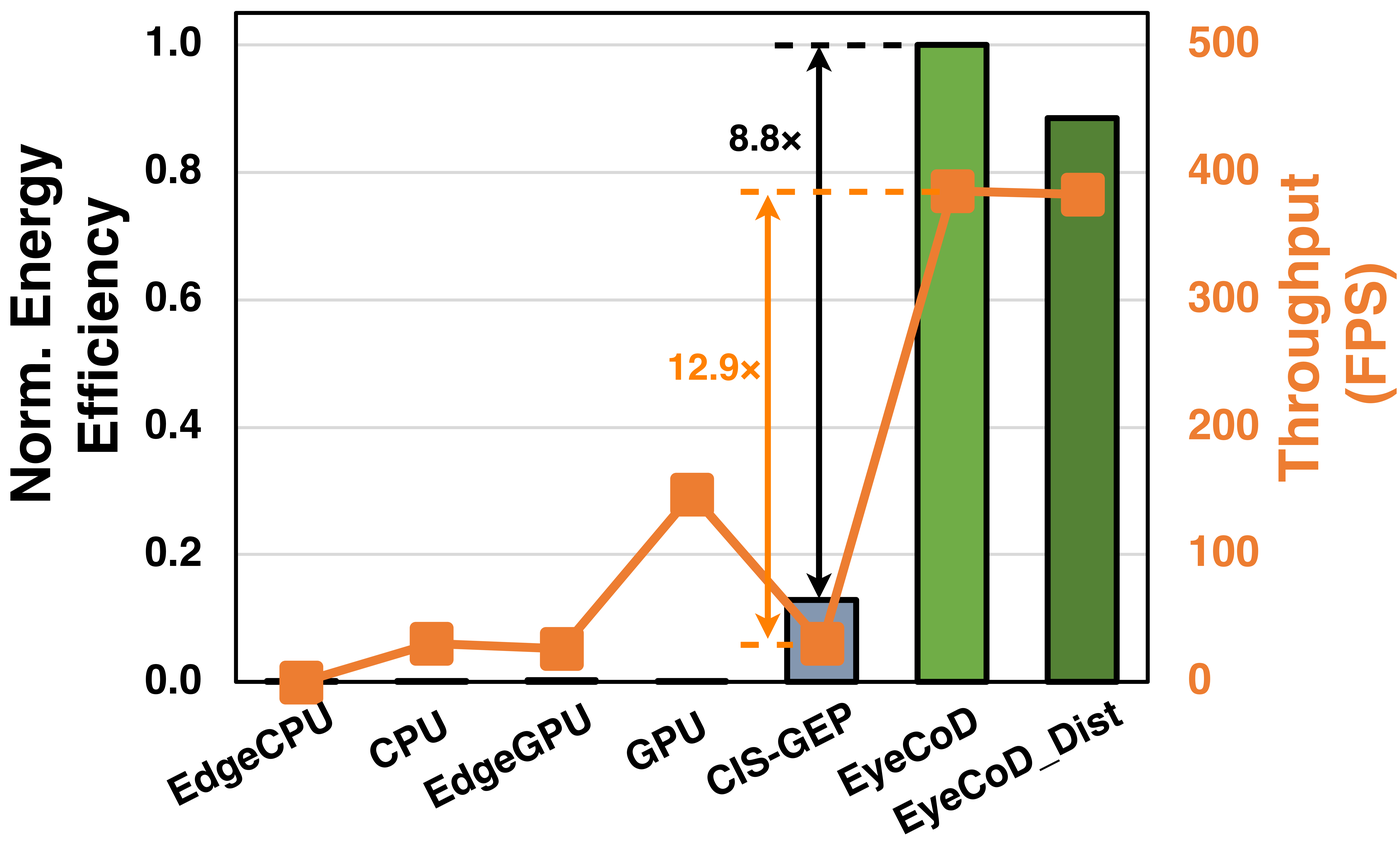
Results. Benchmarked with a cycle-accurate simulator built from a silicon-validated chip, EyeCoD achieves comparable gaze estimation error (~3.2°) with 69.2% fewer FLOPs, and comparable segmentation mIOU with 16× fewer FLOPs (32× after 8-bit quantization). End to end, EyeCoD delivers 2965.8×, 12.7×, 14.8×, 2.6×, and 12.9× throughput improvements over EdgeCPU, CPU, EdgeGPU, GPU, and the prior-art CIS-GEP processor, respectively, with 8.8× better energy efficiency than CIS-GEP; a five-chip distributed version (EyeCoD_Dist) still keeps 7.7× the energy efficiency.
Follow-up: a single-chip demo. In the spirit of EyeCoD, we also built i-FlatCam, a version dedicated solely to eye tracking that fits on a single chip for live, integrated demonstration. The board below is that on-silicon test chip in action—this demo won first place in the University Demo competition at DAC 2022.

By co-designing the camera, algorithm, and accelerator together, EyeCoD shows that replacing lens-based cameras with lensless ones—while exploiting the resulting opportunities in the algorithm and hardware—can meet both the high-throughput and small-form-factor requirements that next-generation VR/AR eye tracking needs.