
Efficient DNN Training
Model compression has been extensively studied for light-weight inference; popular means include network pruning, weight factorization, network quantization, and neural architecture search, among many others. On the other hand, the literature on efficient training appears to be much sparser: DNN training still requires us to fully train the over-parameterized neural network. Here we focus on reducing total training time and training energy costs, aiming at deployment on resource-constrained platforms, e.g., FPGAs, ASICs, mobile, and IoT devices. Below are three of the most recent works putting huge effort toward the efficient training goal.
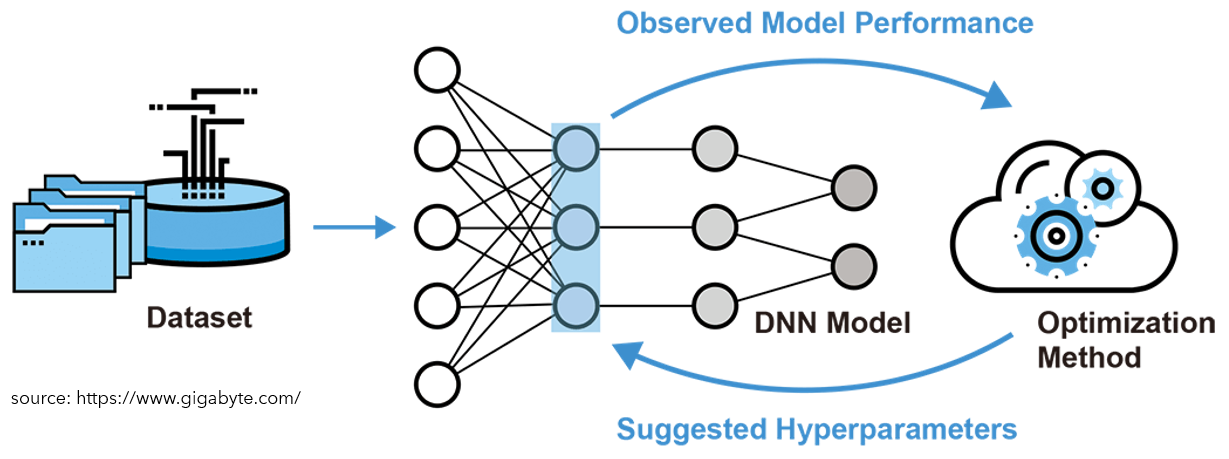 General DNN Training Scheme.
General DNN Training Scheme.
- E^2 Train (NeurIPS 2019): Aiming to conduct more energy-efficient training of CNNs so as to enable on-device training, this paper strives to reduce the energy cost during training by dropping unnecessary computations from three complementary levels: stochastic mini-batch dropping on the data level; selective layer update on the model level; and sign prediction for low-cost, low-precision back-propagation on the algorithm level.
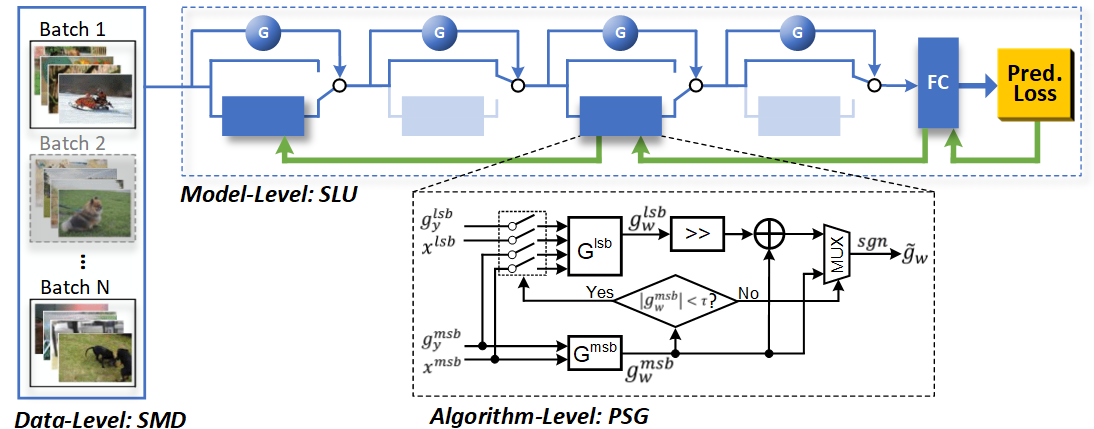
Fig.1 - An illustration of the E^2 Train framework. On the data level, we adopt stochastic mini-batch dropping to aggressively reduce the training cost by letting it see fewer mini-batches; on the model level, we dynamically skip a subset of layers during both feed-forward and back-propagation; on the algorithm level, we propose a novel predictive sign gradient descent (PSG) algorithm, which predicts the sign of gradients using low-cost bit-level predictors, thereby completely bypassing the costly full-gradient computation.
Benefiting from the aforementioned three techniques, we are able to achieve over 80% total training energy cost savings measured on FPGA. For example, when training ResNet-74 on CIFAR-10, we achieve aggressive energy savings of >90% and >60%, while incurring a top-1 accuracy loss of only about 2% and 1.2%, respectively. When training ResNet-110 on CIFAR-100, over 84% training energy savings are achieved without degrading inference accuracy.
- EB Train (ICLR 2020 Spotlight): This paper bridges the gap between the Lottery Ticket Hypothesis and the efficient training goal. Since the identification of winning tickets still requires the costly train-prune-retrain process, limiting their practical benefits, this paper discovers for the first time that the winning tickets can be identified at the very early training stage (Early-Bird (EB) tickets) via low-cost training schemes, and proposes a mask distance metric that can be used to identify EB tickets with low computational overhead, without needing to know the true winning tickets that emerge after full training. Therefore, we can leverage the existence of EB tickets and the proposed mask distance to develop an efficient training method that first identifies EB tickets via low-cost schemes and then continues to train merely the EB tickets towards the target accuracy.
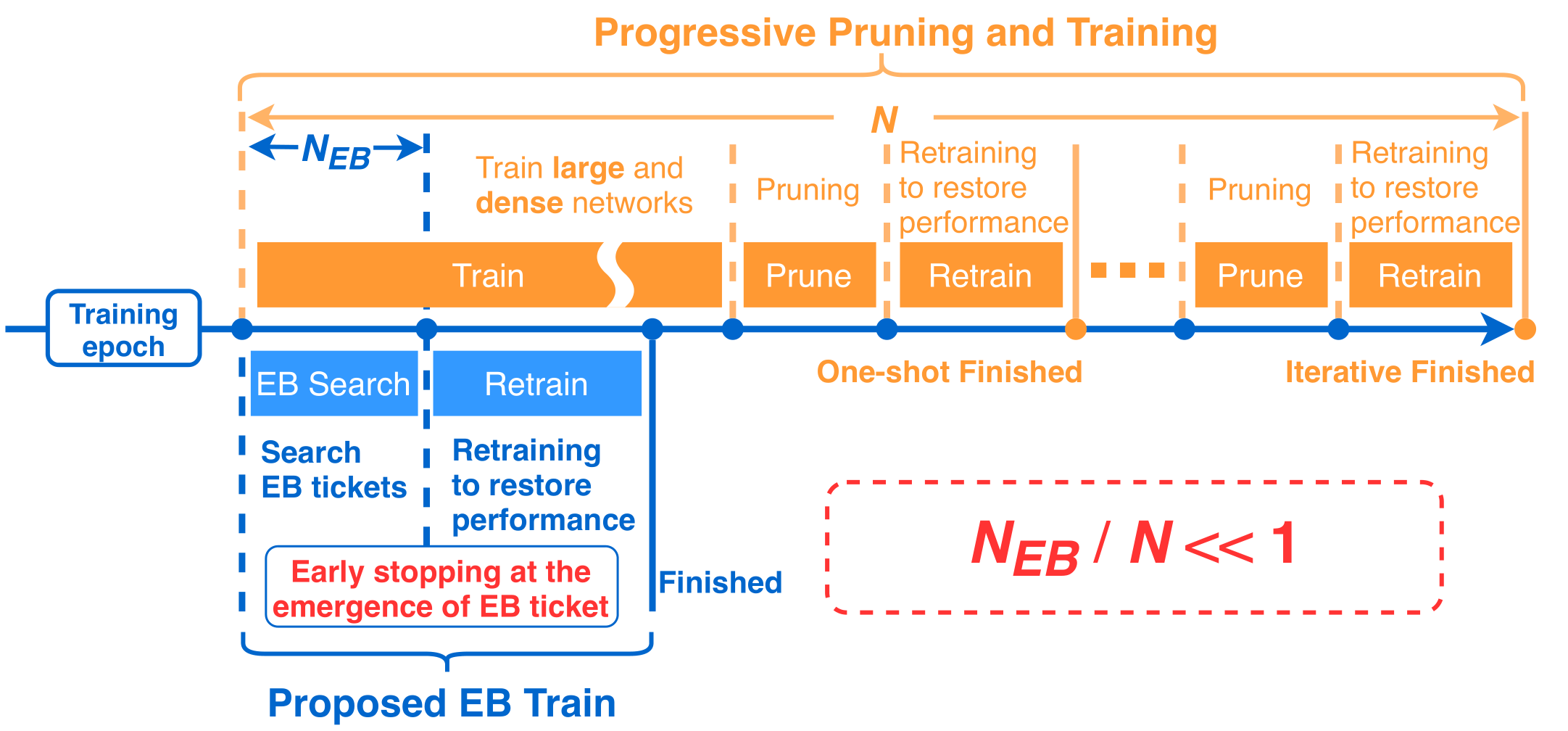
Fig.2 - A high-level overview of the difference between EB Train and existing progressive pruning and training. In particular, the progressive pruning and training scheme adopts a three-step routine of 1) training a large and dense model, 2) pruning it, and 3) then retraining the pruned model to restore performance, and these three steps can be iterated. The first step often dominates (e.g., occupying 75% of the training FLOPs) in terms of training energy and time costs. EB Train, on the other hand, replaces the aforementioned steps 1 and 2 with a lower-cost step of detecting the EB tickets.
Experiments based on various deep networks and datasets validate: 1) the existence of EB tickets, and the effectiveness of the mask distance metric in efficiently identifying them; and 2) that the proposed efficient training via EB tickets can achieve up to 4.7× energy savings while maintaining comparable or even better accuracy, demonstrating a promising and easily adoptable method for tackling the often cost-prohibitive deep network training.
- FracTrain (NeurIPS 2020): This paper proposes FracTrain, which integrates: 1) progressive fractional quantization, which gradually increases the bitwidth of activations, weights, and gradients such that it does not reach the precision of SOTA static quantized DNN training until the final training stage, and 2) dynamic fractional quantization, which assigns bitwidths to both the activations and gradients of each layer in an input-adaptive manner, for only “fractionally” updating layer parameters.
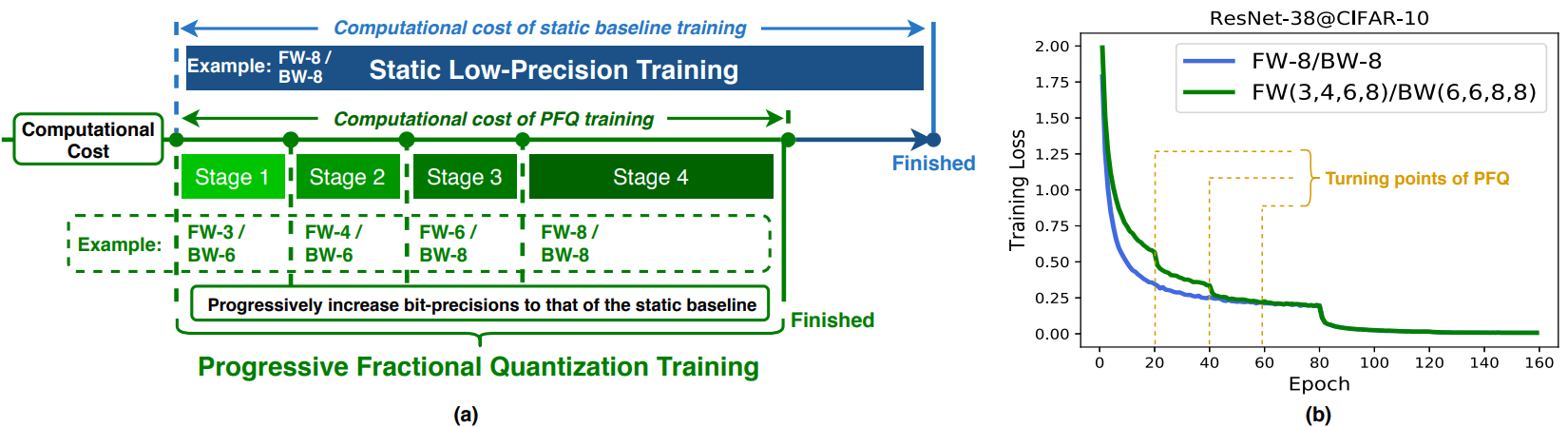
Fig.3 - (a) A high-level view of the proposed PFQ vs. SOTA low-precision training, where PFQ adopts a four-stage precision schedule to gradually increase the precision of weights, activations, gradients, and errors up to that of the static baseline, which here employs 8-bit precision for both the forward and backward paths, denoted as FW-8/BW-8, and (b) the corresponding training loss trajectory.
Extensive simulations and ablation studies (six models, four datasets, and three training settings including standard, adaptation, and fine-tuning) validate the effectiveness of FracTrain in reducing computational cost and hardware-quantified energy/latency of DNN training while achieving a comparable or better (-0.12% ~ +1.87%) accuracy. For example, when training ResNet-74 on CIFAR-10, FracTrain achieves 77.6% and 53.5% computational cost and training latency savings, respectively, compared with the SOTA baseline, while achieving a comparable (-0.07%) accuracy.
- ShiftAddNet (NeurIPS 2020): This paper presents ShiftAddNet, whose main inspiration is drawn from a common practice in energy-efficient hardware implementation, that is, multiplication can instead be performed with additions and logical bit-shifts. We leverage this idea to explicitly parameterize deep networks in this way, yielding a new type of deep network that involves only bit-shift and additive weight layers.
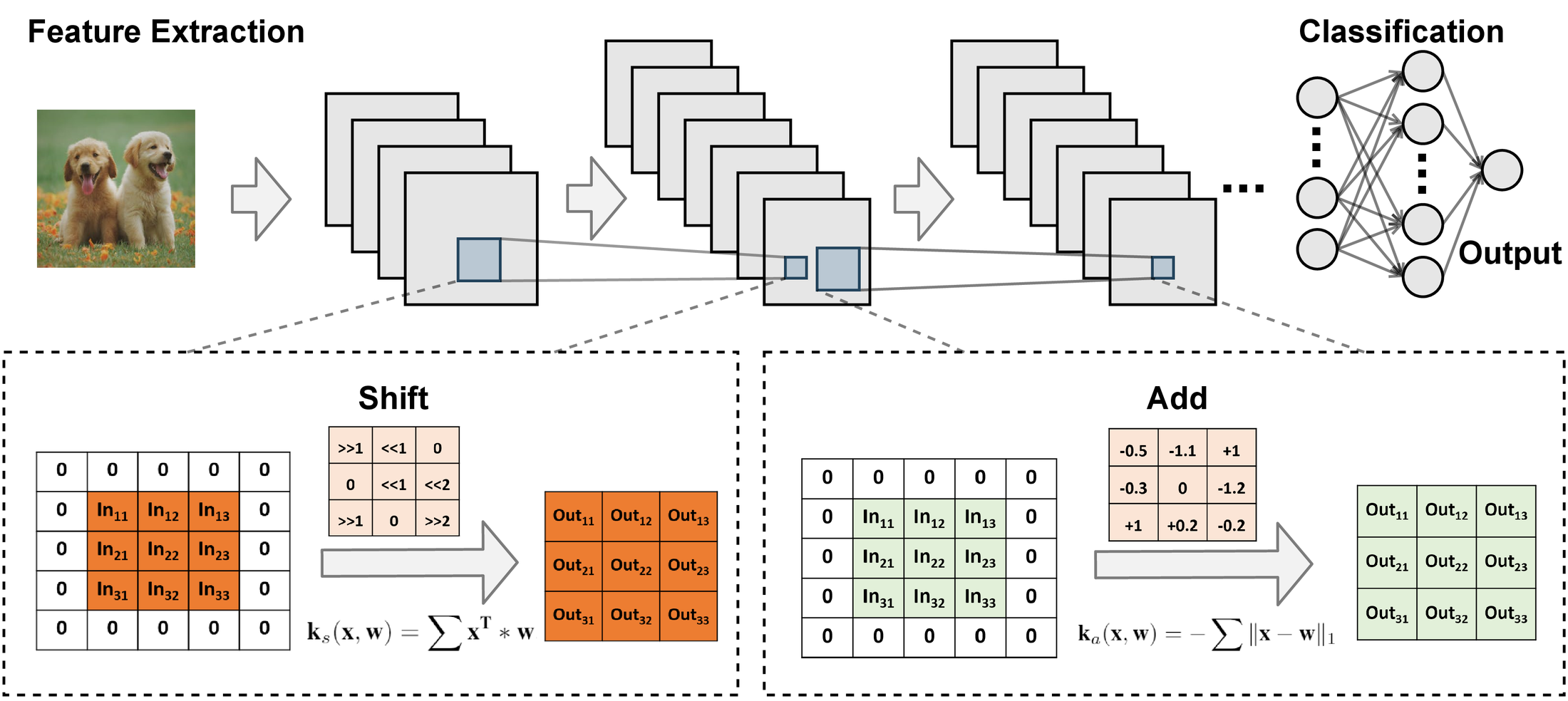
Fig.4 - Overview structure of ShiftAddNet.
This hardware-inspired ShiftAddNet immediately leads to both energy-efficient inference and training, without compromising the expressive capacity compared to standard DNNs. The two complementary operation types (bit-shift and add) additionally enable finer-grained control of the model’s learning capacity, leading to a more flexible trade-off between accuracy and (training) efficiency. Compared to existing DNNs or other multiplication-less models, ShiftAddNet aggressively reduces the hardware-quantified energy cost of DNN training and inference by over 80%, while offering comparable or better accuracies.